- 软件



/简体中文/
/英文/

/简体/

/多国语言[中文]/

/简体/

/简体/

/简体/

/简体/

/简体/

/简体/
 网易木木助手-网易木木模拟器下载 v2.7.13.200官方版
网易木木助手-网易木木模拟器下载 v2.7.13.200官方版 雷电模拟器安卓9-雷电模拟器安卓9.0下载 v9.0.33.0官方版
雷电模拟器安卓9-雷电模拟器安卓9.0下载 v9.0.33.0官方版 兆懿运行平台(移动应用运行平台)下载 v1.1.0官方版
兆懿运行平台(移动应用运行平台)下载 v1.1.0官方版 MuMu手游助手-MuMu手游助手下载 v1.5.0.6官方版
MuMu手游助手-MuMu手游助手下载 v1.5.0.6官方版 华为移动应用引擎电脑版-华为移动应用引擎下载 v1.2.1.1官方版
华为移动应用引擎电脑版-华为移动应用引擎下载 v1.2.1.1官方版 360安全卫士电脑版官方下载-360安全卫士下载 v13.0.0.2122官方版
360安全卫士电脑版官方下载-360安全卫士下载 v13.0.0.2122官方版 万能录屏大师-万能录屏大师下载 v1.0官方版
万能录屏大师-万能录屏大师下载 v1.0官方版 野葱录屏-野葱下载 v2.4.1473.249官方版
野葱录屏-野葱下载 v2.4.1473.249官方版 网红主播音效助手-网红主播音效助手下载 v5.2官方版
网红主播音效助手-网红主播音效助手下载 v5.2官方版 易谱软件下载-易谱ziipoo下载 v2.5.6.8官方版
易谱软件下载-易谱ziipoo下载 v2.5.6.8官方版软件Tags: FictionDown(网络小说爬取工具)
FictionDown是一款网络小说爬取工具,支持自动校对、多格式转换,解决章节缺失和章节顺序错乱的问题,内置了简单的广告过滤,实际上大部分需要手动删除!
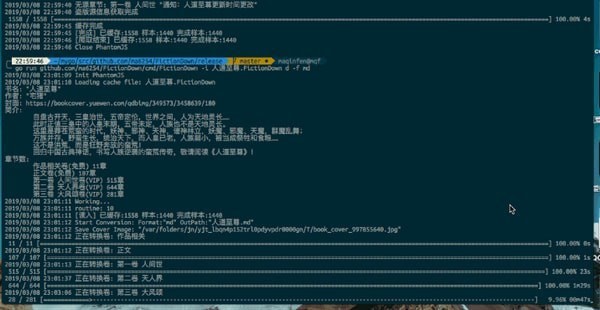
以起点为样本,多站点多线程爬取校对
支持导出txt,以兼容大多数阅读器
支持导出markdown,可以用pandoc转换成epub,保留书本信息、卷结构、作者信息
内置简单的广告过滤(现在还不完善)
用Golang编写,安装部署方便,外部依赖只有PhantomJS
使用方法输入起点链接
获取到书本信息,开始爬取每章内容,遇到vip章节放入Example中作为校对样本
手动设置笔趣阁等盗版小说的对应链接,tamp字段
再次启动,开始爬取,只爬取VIP部分,并跟Example进行校对
手动编辑对应的缓存文件,手动删除广告和某些随机字符(有部分是关键字,可能会导致pandoc内存溢出或者样式错误)
d -f md生成markwown
用pandoc转换成epub,pandoc -o xxxx.epub xxxx.md
功能介绍未实现功能
爬取起点的时候带上Cookie,用于爬取已购买章节
支持刺猬猫(即“欢乐书客”)
支持直接输出epub,不需要pandoc
支持小说站内搜索
多线程转换md
整理main包中的面条逻辑
整理命令行参数风格
在windows下,md转换到epub时有路径问题
完善广告过滤
简化使用步骤
优化log输出
书本简介也应该为HTML。即<p>??</p>而不是现在的用\t和\n
更新日志小说站内搜索
命令行整理
修改站点匹配结构
各个输出格式略作整理
 雷电模拟器国际版-LDPlayer(雷电模拟器海外版)下载 v4.0.37官方版手机软件
雷电模拟器国际版-LDPlayer(雷电模拟器海外版)下载 v4.0.37官方版手机软件
 华为EC6110-T免拆刷机固件下载 v1.0免费版硬件检测
华为EC6110-T免拆刷机固件下载 v1.0免费版硬件检测
 咩播直播软件-咩播直播软件下载 v0.13.102官方版媒体其他
咩播直播软件-咩播直播软件下载 v0.13.102官方版媒体其他
 联想M7405D驱动下载-联想M7405D打印机驱动下载 v1.0官方版万能驱动
联想M7405D驱动下载-联想M7405D打印机驱动下载 v1.0官方版万能驱动
 Ghidra-Ghidra(反汇编工具)下载 v9.0.4中文版编程开发
Ghidra-Ghidra(反汇编工具)下载 v9.0.4中文版编程开发
 雷云2.0下载-雷蛇云驱动(Razer Synapse 2.0)下载 v2.21.24.34官方版万能驱动
雷云2.0下载-雷蛇云驱动(Razer Synapse 2.0)下载 v2.21.24.34官方版万能驱动
 Office2021官方下载免费完整版-Microsoft Office 2021正式版下载 16.0.14701.20262官方版办公软件
Office2021官方下载免费完整版-Microsoft Office 2021正式版下载 16.0.14701.20262官方版办公软件
 京瓷FS-C8520MFP驱动-京瓷FS-C8520MFP打印机驱动下载 v6.1.0826官方版万能驱动
京瓷FS-C8520MFP驱动-京瓷FS-C8520MFP打印机驱动下载 v6.1.0826官方版万能驱动
 柯尼卡美能达C7222驱动-柯尼卡美能达C7222驱动下载 v1.0官方版万能驱动
柯尼卡美能达C7222驱动-柯尼卡美能达C7222驱动下载 v1.0官方版万能驱动







